
Implementing AI in Healthcare (and why it's a lot harder than you think)

Initially, when deciding what to work on within AI, I naturally gravitated to a space where I perceived I could make a lot of impact: healthcare.
After building a bunch of models, including one that had 93% accuracy, I was thinking about implementing these in a hospital setting. Of course, it seemed like a good option because healthcare professionals would benefit from a tool that could make workflows more efficient and accurate (especially because of burnout and the loss of workers in the space).
Turns out, implementation is a MUCH HARDER path than I thought- there are so many factors to consider and so many problems to solve before implementing all these models. Despite the rapidly increasing amount of papers that come out each year, the rate at which they get implemented is lagging behind and there’s really no progress being made (as shown in the figure below).

The intention in this post is not to give a solution on how to solve this problem (since the problem is very multi-faceted and complex)- this is something I am currently looking into. I want to outline the problem in an organized manner that lays out the considerations, factors, problems, and challenges that are hindering the implementation of models.
I will be summarizing the papers I’ve read about this by breaking down the stages of a predictive model, including problems and challenges, as well as considerations to make in regard to the healthcare system.
A Predictive Model’s Five Stages
1. Prioritization
It is important to identify what you’re looking for/what problem you’re addressing because AI tools should be contextualized in an existing workflow. Specifically, the researcher should know the status quo (how the disease is detected manually in the hospital).
This ensures that the algorithm’s evaluation matches the real-time environment, making it appropriate for the use case and bringing utility to the end users. A great way to do this is to send out surveys asking about processes medical professionals find tedious, time-intensive, and/or inefficient. If you do end up formulating a tool they could use, it would be beneficial to get validation on that through surveys as well.
2. Assessment
One should know how well similar tools have performed in other hospitals and institutions, and what the expected resources should be. These considerations help to understand how to make a feasible and effective model.
3. Development
This is the research/scientific stage where there needs to be a focus on features in the dataset, model development, and evaluating algorithm performance on retrospective data.
The model should be built with bias and fairness considerations, so it is robust and adaptable to different people’s backgrounds and races. Most datasets contain data that isn’t a true representation of the population in that region; the large majority belongs to white people or men, leaving out minorities. For instance, this is the REMBRANDT dataset that I’m training my tumour grading model on; below, you can see the difference in patients who are male vs. female and white vs. other races)
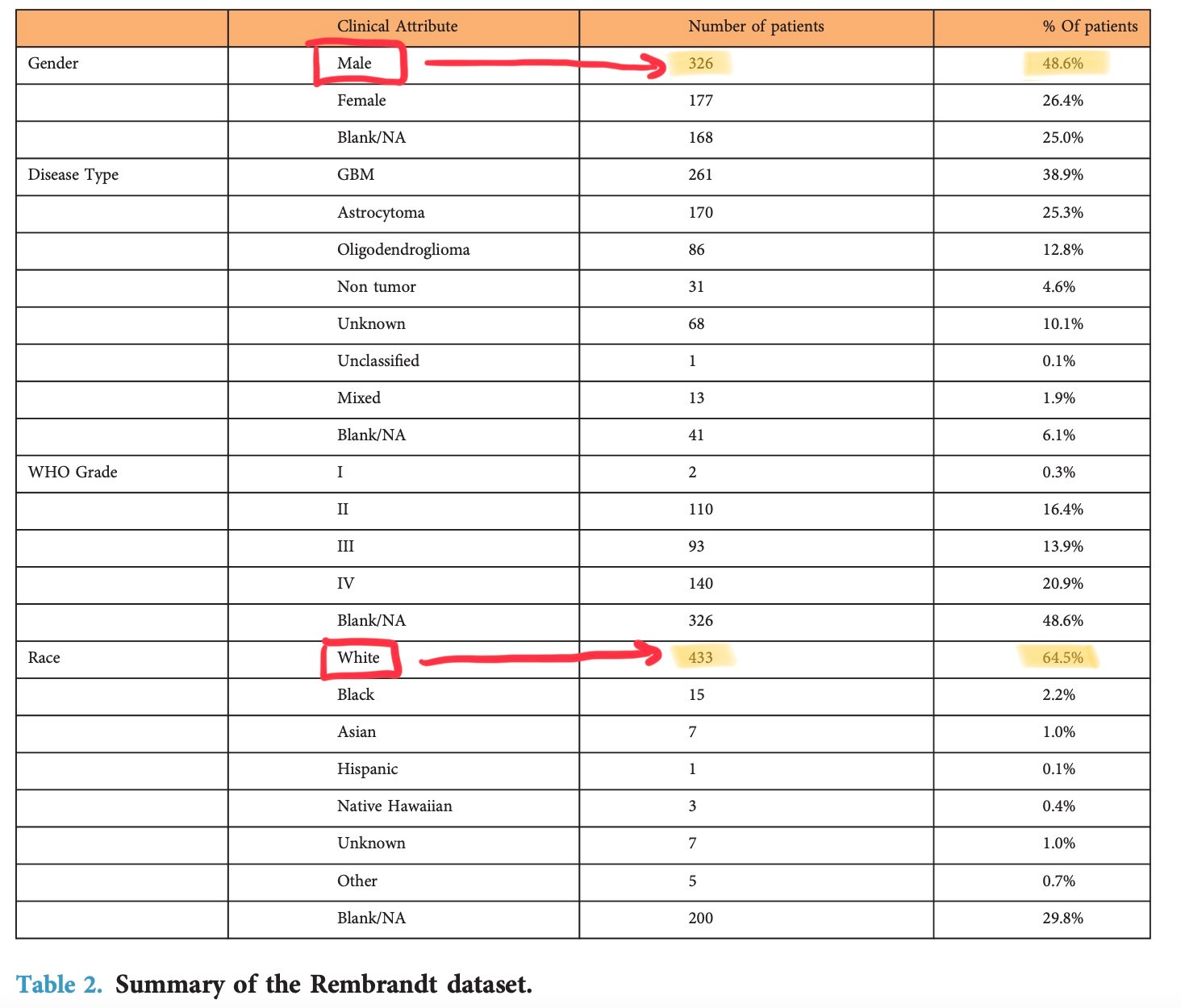
To mitigate this, the model should be trained, validated, and tested, on more balanced data from different sources. Especially in a place like Toronto, where there is a chain of hospitals in the downtown region, collaborating with each other to get access to datasets makes a big difference in accuracy when implementing it in a real-world setting. Getting the model to the point it isn’t biased/unfair is a long and tedious process; not having good accuracy after running the model on a lot of data can be demotivating for researchers and they end up dropping their projects.

The model should also be aligned with the hospital’s existing workflow and have a good user interface. This means that it should be user-friendly, self-instructing, time-saving, and easy to use for medical professionals.
Another factor is typically considered is explainability. AI models are “black boxes 📦” because, although doctors might understand their architecture, they won’t know exactly how the models are getting to their final prediction.

A model could be relying on the wrong pieces of information to get its output. For instance, there was a deep learning model that relied on the x-ray scanner’s location to screen for pneumonia, which is obviously the wrong variable to rely on. Having explainable AI can ensure that the model is making its decision by prioritizing the right variables, making it easier for doctors to understand the model’s thought process.
An important thing to think about when doing in silico evaluation is: how should the false positives and negatives be balanced and what would be the risks/costs associated with specific thresholds.
4. Deployment and Evaluation
This stage is the most crucial and the one which requires the most time, energy, and funds. It consists of a “technical-operational handoff” in which you transfer the model into a clinical setting.
The main challenge here is that real-time data is VERY different from retrospective data the model trained on. This data requires more flexibility for the feature extractions and needs to be able to do real-time preprocessing to remove noise and other unnecessary artifacts before passing it through the model.
In my brain tumour projects, for example, you need to do structural preprocessing, like skull-stripping, where you take out the skull and non-brain areas, like the eyes that might be displayed in an MRI scan.

Since the brain tumour model was trained on skull-stripped images, you need to make sure that there’s a way to skull-strip the MRI scans in real-time before passing it into the implemented model (so there is a consistent input).
And this is all considering that the patient complies with data sharing for the AI model to output its prediction; they might be pretty reluctant about this, especially because, if the data gets into the wrong hands, there could be a lot of security issues. Below is an example of personal data hidden in an MRI- since the scan is taken from 3 dimensions, the different angles could be reconstructed to identify whose scan it is.

There also needs to be some sort of platform integrated into the setting (e.x. for alerts to be seen), which means possible barriers with infrastructure. There needs to be a smooth system that incorporates human-computer interaction.
Because of the risk of immediately letting the model weigh in on real-time decisions with a medical professional, there is usually a “silent period” initiated to make sure that the in silico performance approximates the real-time accuracy + the bias problems are not a barrier to actual integration. After getting to this point, there will usually be a hospital-wide study to assess the tool's success.
5. Maintenance and Operations
The last step is concerned with how the algorithm is to be updated and how it will respond to changes in the underlying data. This should be a constant process.
You also need someone responsible for curating + funding projects as well as people maintaining the model after deployment.
There are many technical barriers that need to be overcome to implement a model in the healthcare system. But, before that, the healthcare system needs to adapt as well.
Considerations to make with the Healthcare System
Exogenous conditions beyond the direct control of the healthcare system
Existing laws and policies have not kept pace with technological developments - only one less than one-fifth of all countries (17%) reported to have a national policy or strategy regulating the use of big data in the health sector.
A big problem with the lack of policies is accountability; if something happens, who has responsibility? Would it be the AI system itself, the developers of the system, or the institution(s) that regulated the use of these systems in a clinical setting?
If there is a policy in which medical professionals get their licences revoked if they make a detrimental wrong decision, even if it was based on AI’s predictions, they will be more stressed and less likely to depend on AI.
The Canadian Association of Radiologists has actually thought about this and formulated opinions on whose liability it would be based on different levels of automation (see picture)

Integrating AI into healthcare also means that the incoming professionals in the industry would need a restructured curriculum in their education program. I wonder how high-friction it would be to make this change to every education program 🤔

Endogenous requirements in the healthcare system
Access to medical data is commonly too fragmented and limited. We would need a better collection and processing infrastructure for data.
Because of the amount of time this stage takes, a good way to smoothly work through this is to have support from professionals. These people should have a diverse set of knowledge and expertise, like human factor engineers, implementation scientists, data engineers, and people familiar with clinical transformation and EHR workflow.
Each individual hospital shouldn’t have its own plan and strategies for implementation - they should be shared.
Obviously, not everyone will be on the side of implementing AI; there will be resistance. One main reason for this might be that they don’t see the value proposition. Thus, it is crucial to make this obvious, improving their motivation to use AI in their day-to-day tasks.


Overall Thoughts
There are so many factors to consider as well as challenges that need to be resolved in different areas. It just seems high friction to spend so much money and effort on these stages.
And the biggest thing is time. In a paper I read, one detection project for sepsis has been going through the 5 stages for almost 7 years and it literally took 18 months to get to the point where the clinicians were fully satisfied with the tool. Researchers probably won’t continue with implementation after building an accurate model just because of how demotivating this tedious process could be.
This also brings up a really interesting question that I don’t know the answer to: if it takes years to implement one model, there will certainly be another model in the market that is much better for the task at hand. Would you just end up shooting down that project you spent years on?
There needs to be a huge shift in the healthcare and education for medical professionals system that it seems like progress would be really slow.
Another group that is usually overlooked through implementation is the patients- they could just not consent to use the tool and it wouldn’t be used. A key finding in this study mentions that patients understand the advantage of AI in terms of speed and accuracy, but they put a lot of emphasis on “the potential for false-negatives, false-positives, inaccurate or limited training set, lack of context, lack of physical examination, and operator dependence”. Convincing patients is also a huge barrier that would just take time and effort.
Overall, I’m unsure what I could do at an individual level to expedite this process, which I will be looking more into.
If you have any contradicting thoughts/comments on this post (especially if you are a researcher within AI and healthcare), feel free to dm me on Twitter and I would love to talk.
Papers I read about this:
https://vectorinstitute.ai/wp-content/uploads/2020/03/implementing-ai-in-healthcare.pdf
https://www.frontiersin.org/articles/10.3389/fdgth.2021.594971/full
https://www.sciencedirect.com/science/article/pii/S0846537119300063?via%3Dihub
https://www.thelancet.com/action/showPdf?pii=S2589-7500%2822%2900029-2